
本問題では「scikit-learn」のうち「ハイパーパラメータの最適化」について学びます。
本問題の解説はYouTube動画でもご覧いただけます。
【解説動画】 第1回Python3データ分析模擬試験 第39問
※当解説動画シリーズはPythonエンジニア育成推進協会に認定された「Python 3 エンジニア認定データ分析試験」の参考教材です。
問題
次のスクリプトに関する説明のうち誤っているものはどれか。
from sklearn.datasets import load_iris
from sklearn.model_selection import GridSearchCV
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split
iris = load_iris()
X, y = iris.data, iris.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=123)
clf = DecisionTreeClassifier()
param_grid = {‘max_depth’: [3, 4, 5]}
cv = GridSearchCV(clf, param_grid=param_grid, cv=10)
cv.fit(X_train, y_train)
y_pred = cv.predict(X_test)
① このスクリプトではハイパーパラメータである決定木の深さをグリッドサーチにより求めている。
② このスクリプトを複数回実行した場合、求められる決定木の深さの最適値は必ず同じ値となる。
③ このスクリプトで用いられているIrisデータセットには、150枚のアヤメの「がく」や「花びら」の長さと幅、そして花の種類が記録されている。
④ このスクリプトでは10分割の交差検証が実行される。
⑤ このスクリプトで求められる決定木の深さの最適値は必ず3から5の整数のいずれかとなる。
解説
正解は選択肢②です。以下解説します。
コードの確認

選択肢を見る前にコードを確認します。
まずIrisデータセットとmodel_selectionモジュールのGridSearchCVクラスをインポートします。
GridSearchCVクラスはハイパーパラメータ、今回は決定木の深さを最適化するために用います。
そしてtreeモジュールのDecisionTreeClassifierクラスと、model_selectionモジュールのtrain_test_split関数をインポートします。
load_iris 関数でデータセットを読み込みます。
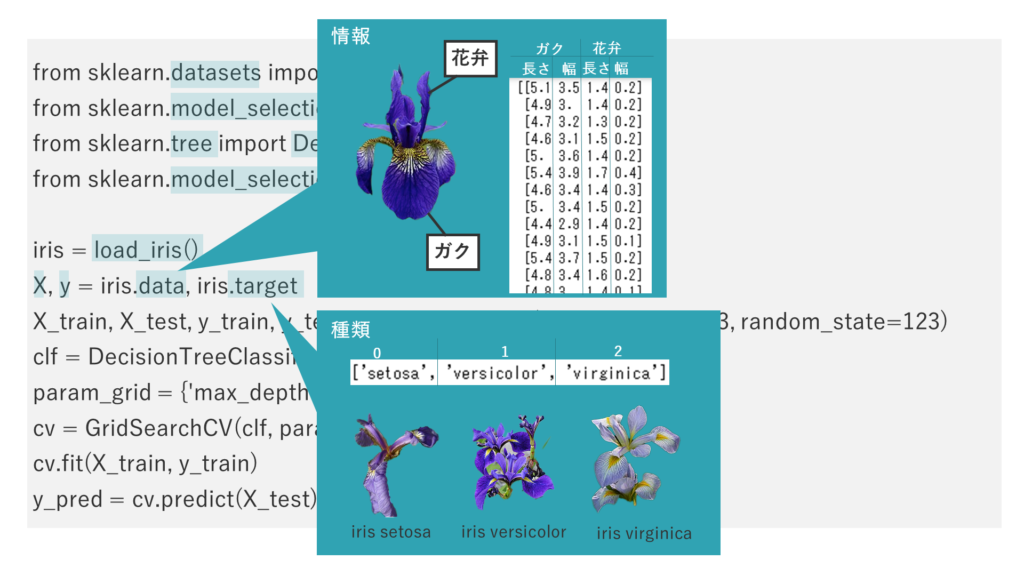
データセットのdataフィールドには、アイリスの花の情報、データセットのtargetフィールドには花の種類が格納されています。それぞれ変数X、yに格納します。
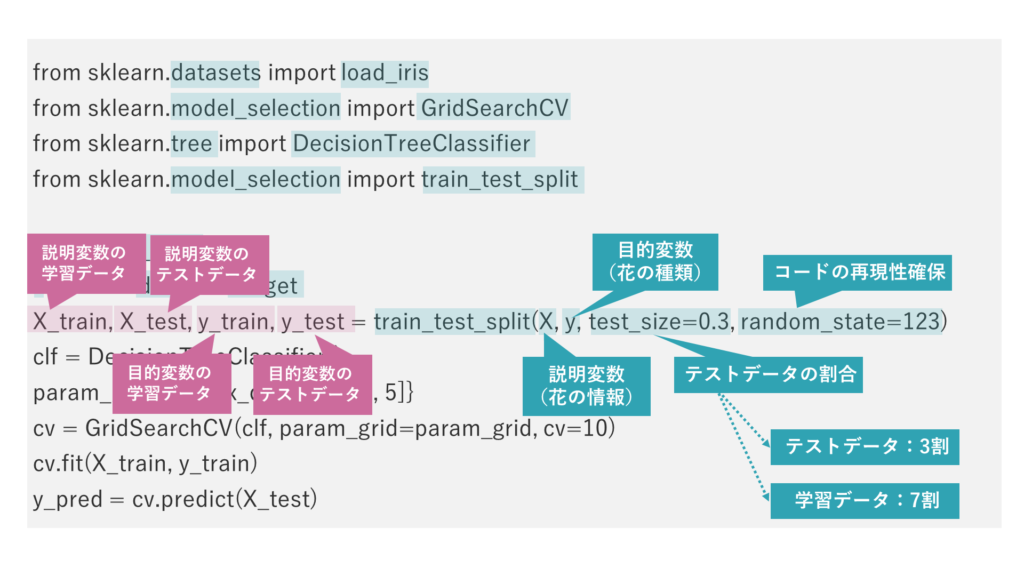
train_test_split関数で、データを分割していきます。
最初の引数に説明変数、次の引数に目的変数を指定し、test_size引数にテストデータの割合を指定します。最後の引数にシード値を指定します。
分割したデータを4つの変数に格納します。
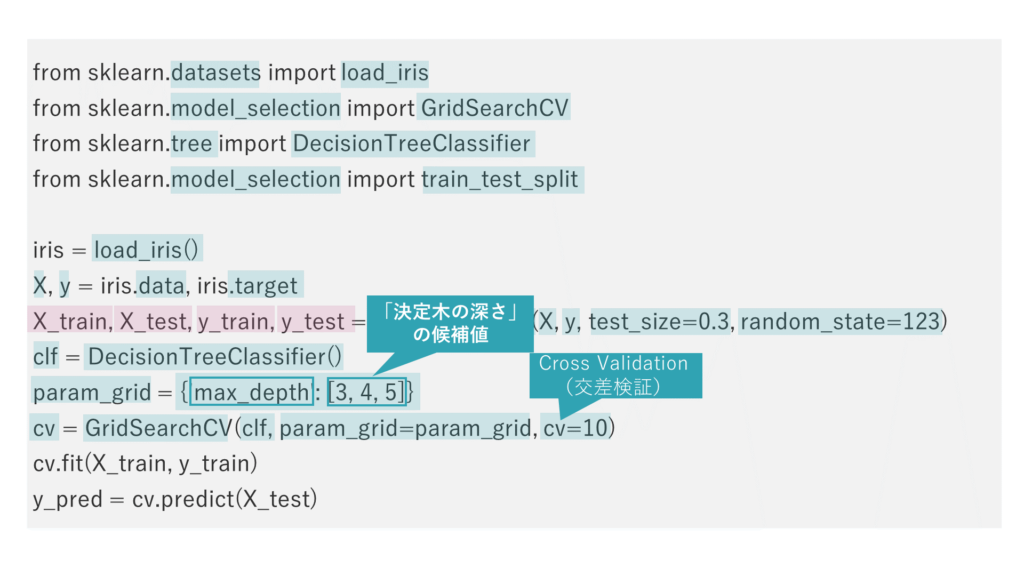
そして、DecisionTreeClassifierクラスのインスタンスを生成し、変数clfに格納します。
決定木の深さの候補として、3つの値(「3」「4」「5」)からなるリストと引数名を対応付ける辞書データをparam_grid変数に格納します。
GridSearchCVクラスをインスタンス化します。最初の引数には決定木、引数param_gridには決定木の深さの候補を指定します。引数cvには、交差検証の手法として、今回は10分割の交差検証を指定します。
これを変数cvに格納します。

fitメソッドに学習データを与えて、cvにデータを学習させ分類モデルを構築します。
ここで、推測された最適な決定木の深さが「3」であることを確認しておきます。
なお先ほどGridSearchCVの引数cvに、10分割の交差検証を指定したため、最適な決定木の深さの値は毎回変わります。
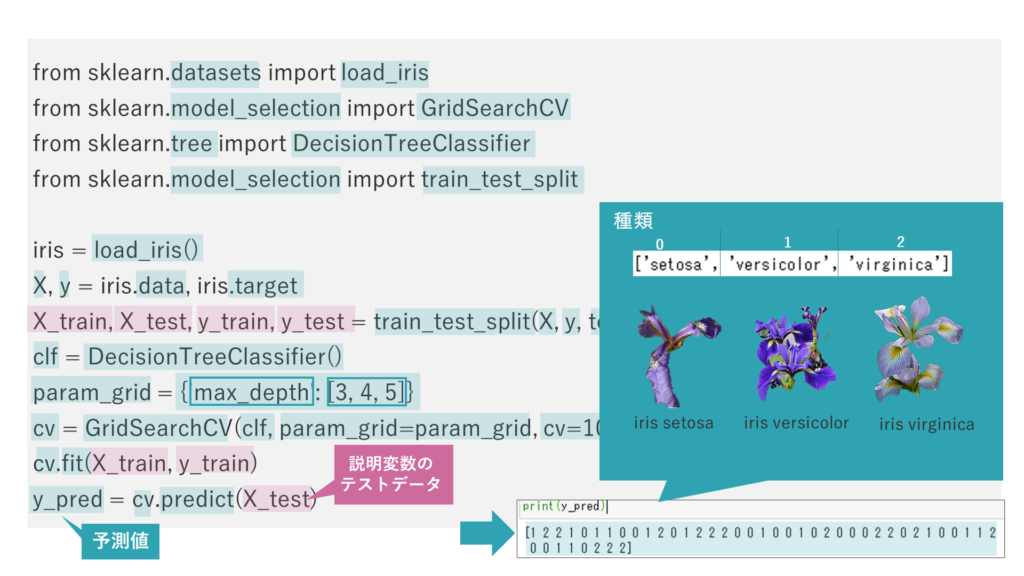
構築したこのモデルを使って、花の「情報」から花の「種類」を予測します。
predictメソッドに花の情報のテストデータを与え、予測される花の種類(目的変数)を取得します。
y_predを出力すると、数字の0、1、2が、花の種類に対応していることを確認できます。
選択肢①

選択肢①は正しい肢です。先ほど確認した通りです。
選択肢②

選択肢②は誤りです。
先ほど確認した通り、最適値は、必ず同じ値になるとは限りません。
選択肢③

選択肢③は正しい肢です。
irisデータセットを出力してみると、0から149まで合計150個のアイリスの情報が記録されていることが確認できます。
選択肢④

選択肢④も正しい肢です。先ほど確認したとおりです。
選択肢⑤

選択肢⑤も正しい肢です。先ほど確認したとおりです。
第1回Python3データ分析模擬試験第39問の解説は以上です。

