
本問題では「scikit-learn」のうち「機械学習を用いて構築した分類モデルの評価指標および混同行列」について学びます。
本問題の解説はYouTube動画でもご覧いただけます。
【解説動画】 第1回Python3データ分析模擬試験 第38問
※当解説動画シリーズはPythonエンジニア育成推進協会に認定された「Python 3 エンジニア認定データ分析試験」の参考教材です。
問題
モデルの評価指標に関する次の記述のうち、誤っているものはどれか。
① 機械学習を用いて構築した回帰モデルの良し悪しを評価する指標に適合率、再現率、F値、正解率がある。これらは混同行列から計算する。
② 適合率は予想するクラスをなるべく間違えないようにしたいときに重視する指標である。
③ 一般的に適合率と再現率はトレードオフの関係にある。つまり、どちらか一方の指標を高くすると、もう一方の指標は低くなる。
④ 正解率は、正例か負例かを問わず、予測と実績が一致したデータの割合を表す。正解率は(tp+tn)/(tp+fp+fn+tn)で計算することができる。
⑤ F値は、適合率と再現率の調和平均として定義される。F値は2*適合率*再現率/(適合率+再現率)で計算することができる。
解説
正解は選択肢①です。以下解説します。
選択肢①

選択肢①は誤りです。
混同行列で計算する適合率、再現率、F値、正解率は、(回帰ではなく)分類モデルの評価指標です。
選択肢②
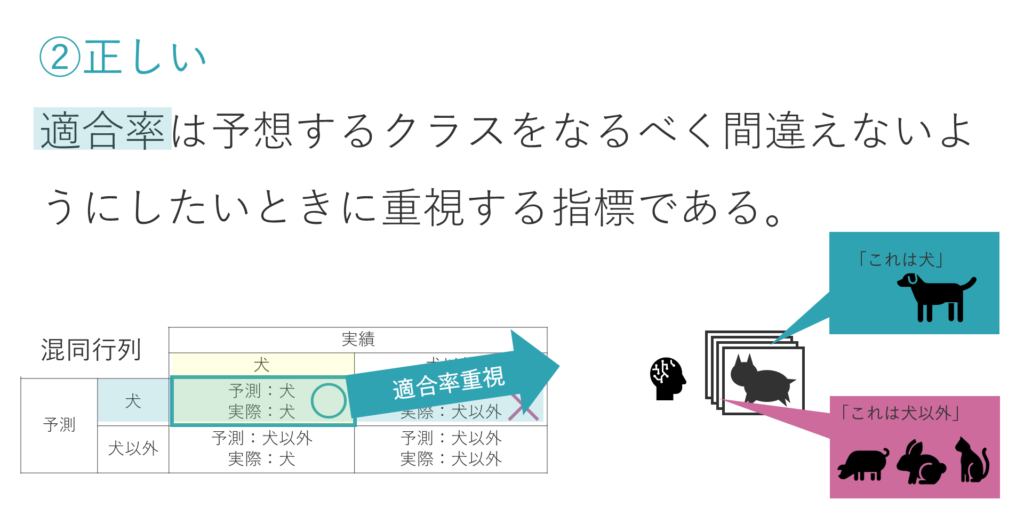
選択肢②は正しい肢です。
例えば、AIに動物の画像をたくさん見せて、それぞれ犬か、それ以外かを判断・予測させるとします。
その判断が正解かどうかは、4パターンに分かれます(右の表)。
適合率というのは、「犬である」と予測した画像のうち、実際に犬、つまり当たりの割合です。
ここで「とにかく適合率を重視して100%に近づけていく」という極端な例を考えてみます。
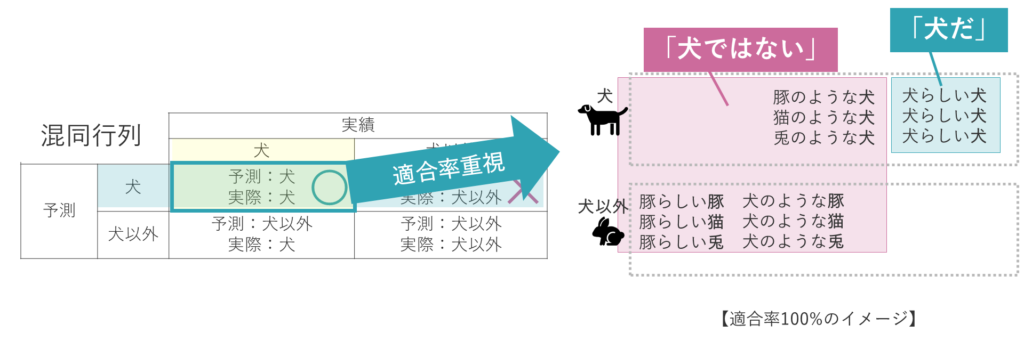
イメージ的には、いろいろな画像がある中で、犬である可能性が特に高いものだけを「犬だ」として、それ以外の大多数の画像を「犬ではない」とすることになります。
そうすることで実際に犬である画像を間違う可能性が減るためです。
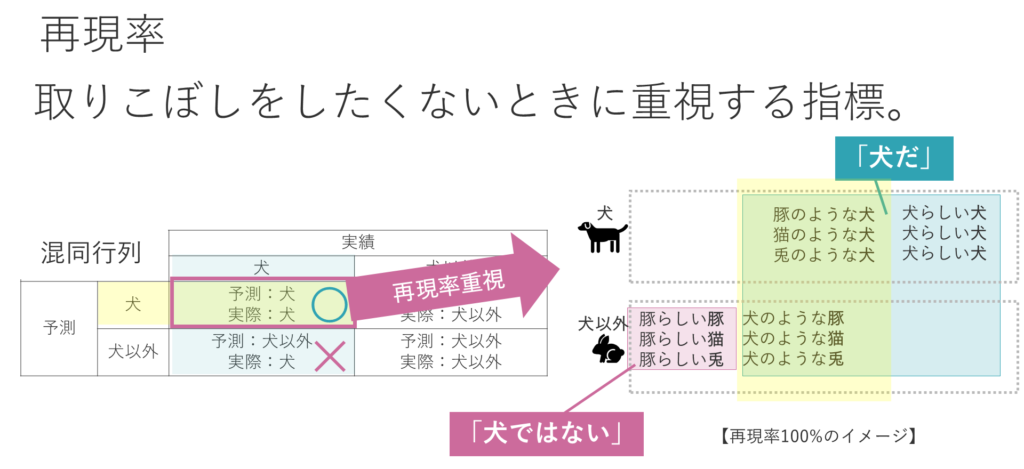
適合率と対の関係にある「再現率」についても確認します。これは先ほどの例でいうと、実際に犬であるうち、予測したものがどれだけ正解だったかという割合です。
ここで「とにかく再現率を重視して100%に近づけていく」という極端な例を考えてみます。
イメージ的には、いろいろな画像がある中で、およそ犬らしいものはすべて「犬だ」といっておいて、犬を取りこぼさないようにすることになります。
以上から、犬かどうかが確実ではない画像に関する取扱いが、再現率と適合率とでは逆であることがわかります。
選択肢③

選択肢③は正しい肢です。
先ほど確認した通り、両者はトレードオフの関係にあるといえます。
選択肢④

選択肢④も正しい肢です。正解率の説明です。
選択肢⑤
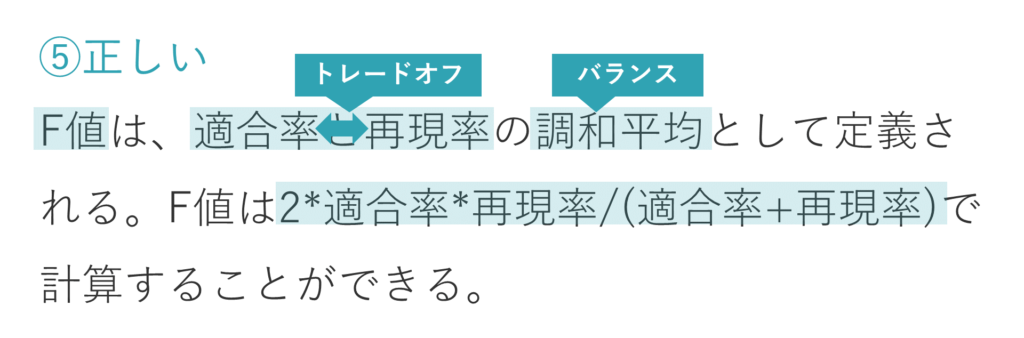
選択肢⑤も正しい肢です。F値の説明です。
先ほど確認したとおり、適合率と再現率はトレードオフの関係にあります。両方の指標をバランス良く用いたい場合には、このようにF値を算出します。
第1回Python3データ分析模擬試験第38問の解説は以上です。

