
本問題では「scikit-learn」のうちボストン住宅価格データセットを用いた回帰について学びます。
本問題の解説はYouTube動画でもご覧いただけます。
【解説動画】 第1回Python3データ分析模擬試験 第36問
※当解説動画シリーズはPythonエンジニア育成推進協会に認定された「Python 3 エンジニア認定データ分析試験」の参考教材です。
問題
次のスクリプトに関する説明のうち誤っているものはどれか。
from sklearn.linear_model import LinearRegression
from sklearn.datasets import load_boston
from sklearn.model_selection import train_test_split
boston = load_boston()
X, y = boston.data, boston.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=123)
lr = LinearRegression()
lr.fit(X_train, y_train )
y_pred = lr.predict(X_test)
① このスクリプトは米国ボストン市郊外の地域別に、住宅価格と特徴量を記録したデータセットを用いて線形回帰を行うものである。
② このスクリプトで行う回帰は住宅価格を特徴量から求める単回帰である。
③ データセットは学習用が7割、テスト用が3割の比率で分割される。
④ X_trainは学習用の説明変数、y_trainは学習用の目的変数である。
⑤ このスクリプトの最終行では、学習したモデルを用いてテスト用の説明変数から予測される目的変数を取得している。
解説
正解は選択肢②です。以下解説します。
コードの確認
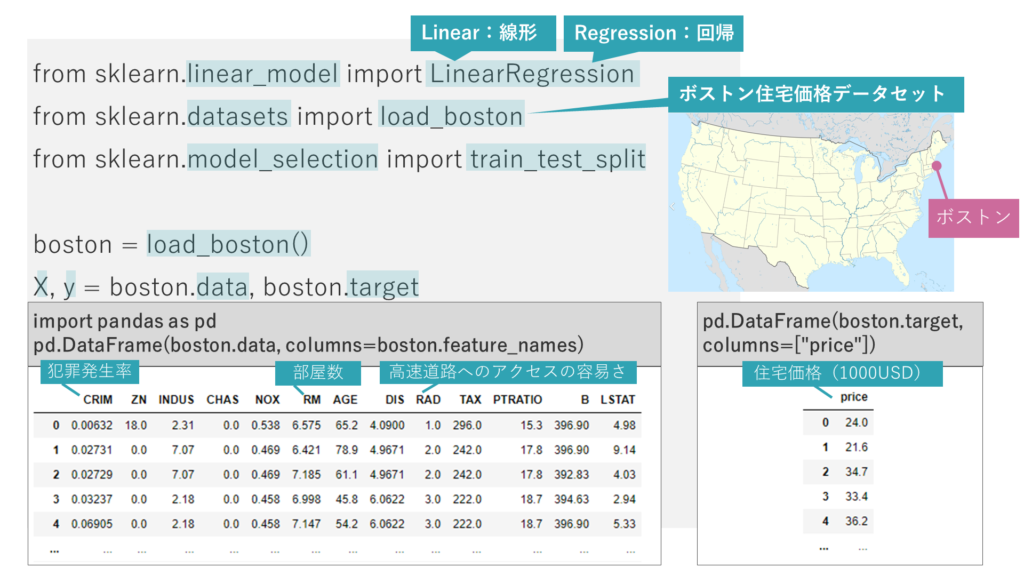
選択肢を見る前にコードを確認します。
まずscikit-learnのliner_modelモジュールのLinearRegressionクラスをインポートして線形回帰の実行準備を行います。
また、scikit-learnのデータセットからボストン住宅価格データセットをインポートします。
このデータセットを用いて、アメリカのマサチューセッツ州ボストン近郊住宅地における1970年代の住宅価格を、各地域の情報から推測します。
コードの3行目でmodel_selectionモジュールのtrain_test_split関数をインポートします。
そしてload_boston 関数でボストン住宅価格データセットを読み込みます。
データセットのdataフィールドには、ボストン近郊の地域ごとに犯罪発生率や、部屋数や、高速道路への利便性などのデータが格納されています。
データセットのtargetフィールドには、ボストン近郊の地域ごとの、住宅価格の中央値が格納されています。それぞれ変数X、yに格納しまします。
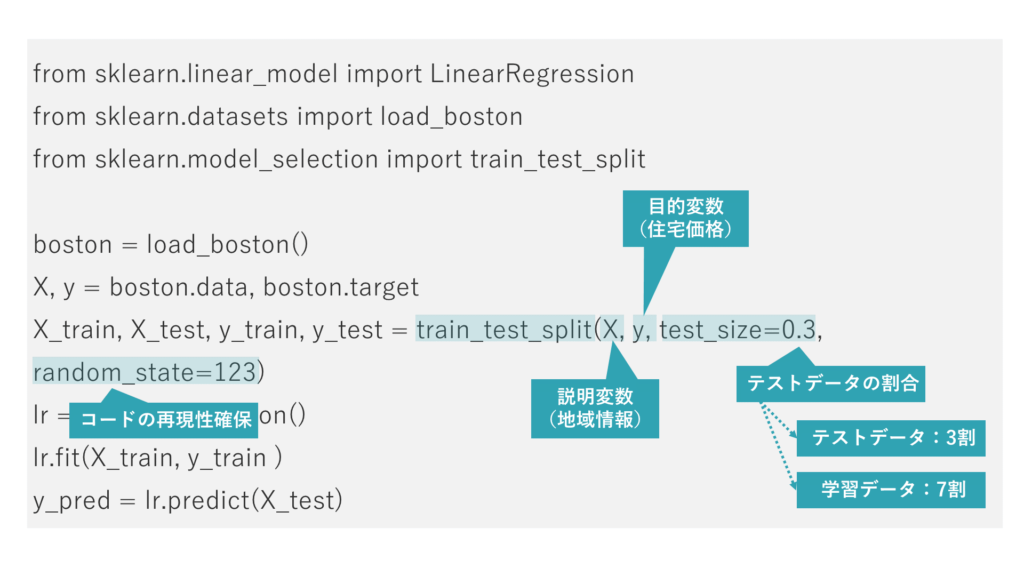
train_test_split関数で、データを分割していきます。
最初の引数Xには地域ごとの情報(説明変数)を、次の引数には住宅価格(目的変数)を指定し、test_size引数にテストデータの割合を指定します。最後の引数にシード値を指定します。

分割したデータを4つの変数に格納します。

LinearRegressionクラスのインスタンスを生成し、変数lrに格納します。fitメソッドに「学習データ」を与えて、lrにデータを学習させ回帰モデルを構築します。
構築したモデルを使って、ボストンの地域情報から住宅価格を予測します。
predictメソッドにボストンの地域情報のテストデータを与え、予測される住宅価格(目的変数)を取得します。
選択肢①

選択肢①は正しい肢です。先ほど確認した通りです。
選択肢②
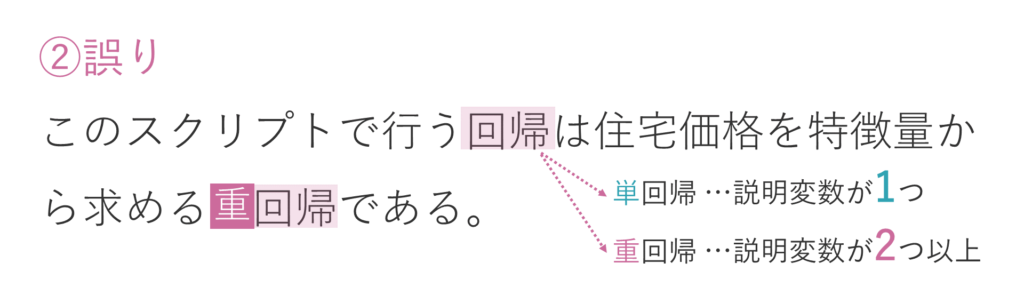
選択肢②は誤りです。
先ほどのコードは複数の説明変数を用いるものですので、「単回帰」ではなく「重回帰」です。
選択肢③

選択肢③は正しい肢です。先ほど確認したとおりです。
選択肢④

選択肢④も正しい肢です。先ほど確認したとおりです。
選択肢⑤

選択肢⑤も正しい肢です。先ほど確認したとおりです。
第1回Python3データ分析模擬試験第36問の解説は以上です。


