
本問題では「scikit-learn」のうち「分類の基礎、分類モデル構築の流れ」について学びます。
本問題の解説はYouTube動画でもご覧いただけます。
【解説動画】 第1回Python3データ分析模擬試験 第34問
※当解説動画シリーズはPythonエンジニア育成推進協会に認定された「Python 3 エンジニア認定データ分析試験」の参考教材です。
問題
分類に関する次の記述のうち、誤っているものはどれか。
① 分類は、データのクラスを予測して分けるタスクであり、未知のデータを教師として利用して各データをクラスに振り分けるモデルを学習する教師あり学習の典型的なタスクである。
② 分類モデルを構築するには、まず手元のデータセットを学習データセットとテストデータセットに分割する。そして、学習データセットを用いて分類モデルを構築し、構築したモデルのテストデータセットに対する予測を評価し、汎化能力を評価する。
③ 学習とモデルの評価は、学習データセットとテストデータセットの分割を繰り返し、モデルの構築と評価を複数回行う方法で行うこともできる。この方法を交差検証という。
④ 学習データセットとテストデータセットの分割は、scikit-learnでは、model_selectionモジュールのtrain_test_split関数を用いて実行することができる。
⑤ scikit-learnのインターフェースでは、学習はfitメソッド、予測はpredictメソッドを用いて実行することができる。
解説
正解は選択肢①です。以下解説します。
選択肢①

選択肢①は誤りです。
分類は教師あり学習の典型的なタスクですが、(未知ではなく)既知のデータを教師として利用します。
余談ですが「教師あり学習の典型的なタスク」に「分類」と「回帰」があり、「分類」はクラスを予測するもの、「回帰」は数値を予測するもの、という違いがあります。
選択肢②

選択肢②は正しい肢です。
分類モデル構築に関する一連の流れが説明されています。
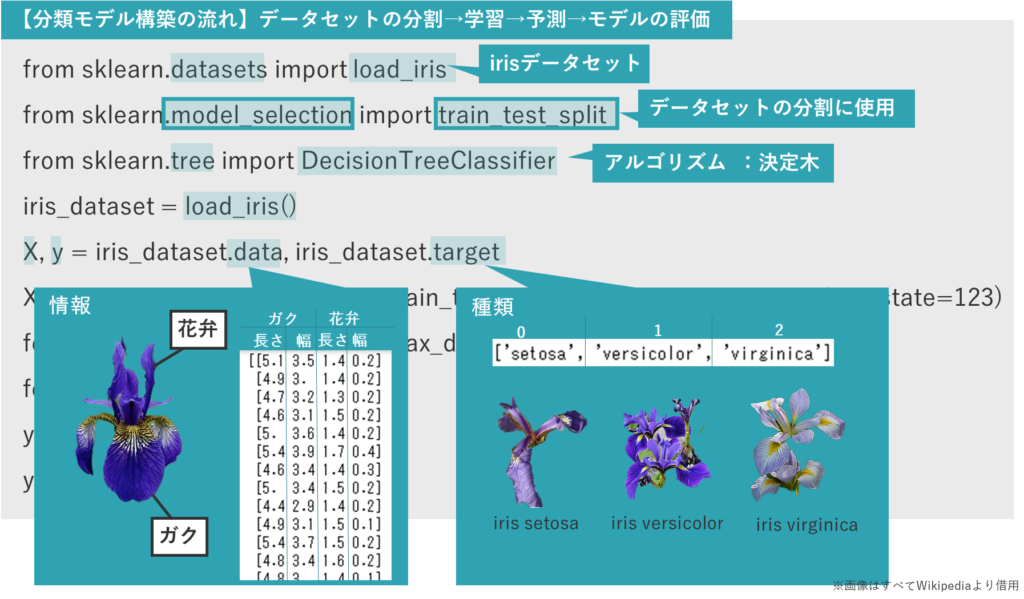
ここで、右のようなIris(アイリス)データセットを用いたサンプルコードで、分類モデル構築の流れを確認します。
まずscikit-learnに付属しているデータセットからIrisデータセットを読み込み、scikit-learnのmodel_selectionモジュールのtrain_test_split関数をインポートします。
この関数でデータセットを学習データとテストデータへと分割します。
そして今回は分類を実行するアルゴリズムとして決定木を使います。
決定木を実行するためにscikitlearnのtreeモジュールのDecisionTreeClassifierクラスをインポートします。
そしてload_iris 関数でデータセットを読み込みます。
データセットのdataフィールドには、アイリスの花の「情報」が、データセットのtargetフィールドにはアイリスの花の「種類」が、格納されています。それぞれ変数X、yに格納します。
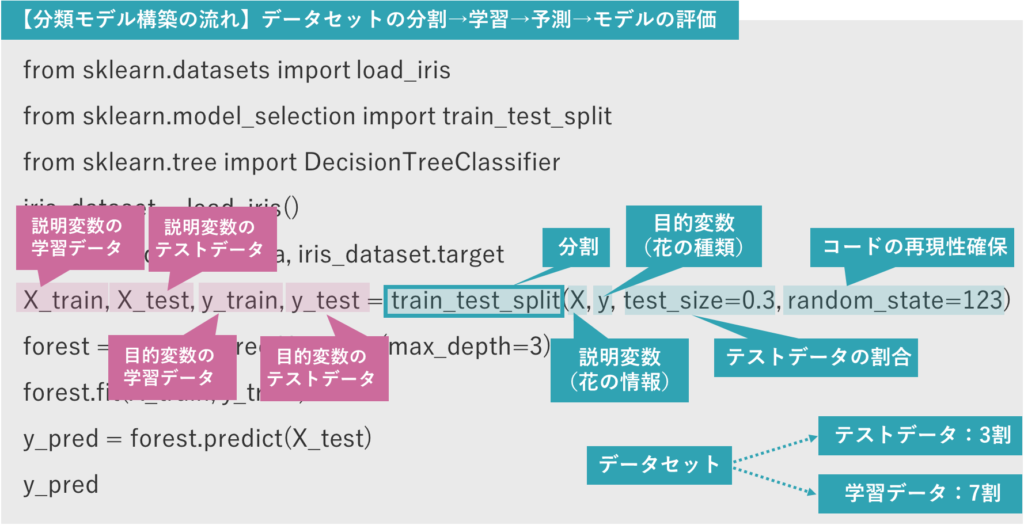
次にtrain_test_split関数で、データを分割していきます。
最初の引数に花の情報(説明変数)を、次の引数には花の種類(目的変数)を指定します。
またtest_size引数にテストデータの割合を指定します。これによってデータセットの分割の割合が、テストデータ3割、学習データ7割となります。
最後の引数にシード値を指定します。
こうして分割したデータを4つの変数に格納します。

そして、決定木の最大の深さを3に指定して、DecisionTreeClassifierクラスのインスタンスを生成し、変数forestに格納します。

fitメソッドに「学習データ」を与え、forestにデータを学習させます。
構築したこのモデルを使って、花の「情報」から花の「種類」を予測します。predictメソッドに花の情報のテストデータを与えて実行し、結果を変数y_predに格納します。
「y_pred」の出力結果を見ると、数字の0、1、2が、花の種類に対応していることを確認できます。

最後に、先ほど構築したモデルの評価(モデルを使って計算した予測値が、実際の値と比べてどの程度正しいかの確認)を行います。
ここではモデルの評価指標として、適合率、再現率、F値を用います。
まずmetricsモジュールのclassification_report関数をインポートします。
この関数に、目的変数のテストデータ、つまり花の種類の実際の値と先ほどの予測値をセットして実行します。
すると花の種類ごとに、適合率、再現率、F値、データの件数が表示されます。
選択肢③

選択肢③は正しい肢です。
先ほどのようなモデルの構築と評価を「複数回」行うという「交差検証」が説明されています。
選択肢④

選択肢④は正しい肢です。先ほど確認した通りです。
選択肢⑤

選択肢⑤も正しい肢です。こちらも先ほど確認した通りです。
第1回Python3データ分析模擬試験第34問の解説は以上です。

