
本問題では「scikit-learn」のうち「機械学習の前処理、カテゴリ変数のエンコーディング、特徴量の正規化」について学びます。
本問題の解説はYouTube動画でもご覧いただけます。
【解説動画】 第1回Python3データ分析模擬試験 第33問
※当解説動画シリーズはPythonエンジニア育成推進協会に認定された「Python 3 エンジニア認定データ分析試験」の参考教材です。
問題
機械学習の前処理に関する次の記述のうち、誤っているものはどれか。
① カテゴリ変数のエンコーディングとは、文字のaを数値の0、bを1、cを2のようにカテゴリ変数を数値に変換する処理をいう。
② One-hotエンコーディングでは、たとえば、テーブル形式のデータのカテゴリ変数の列について、取り得る値の分だけ列を増やして、各行の該当する値の列のみに1を、それ以外の列には0を入力するように変換する処理をいう。
③ 特徴量の正規化とは、たとえば、ある特徴量の値が2桁の数値(数十のオーダ)、別の特徴量の値が4桁の数値(数千のオーダ)のような場合、後者のオーダの特徴量が重視されやすくなるため、尺度を揃える処理をいう。
④ 分散正規化とは、特徴量の平均が1、標準偏差が0となるように特徴量を変換する処理であり、標準化やz変換と呼ばれることもある。
⑤ 最小最大正規化とは、特徴量の最小値が0、最大値が1を取るように特徴量を正規化する処理であり、scikit-learnでは、preprocessingモジュールのMinMaxScalerクラスを用いて実行することができる。
解説
正解は選択肢④です。以下解説します。
選択肢①

選択肢①は正しい肢です。
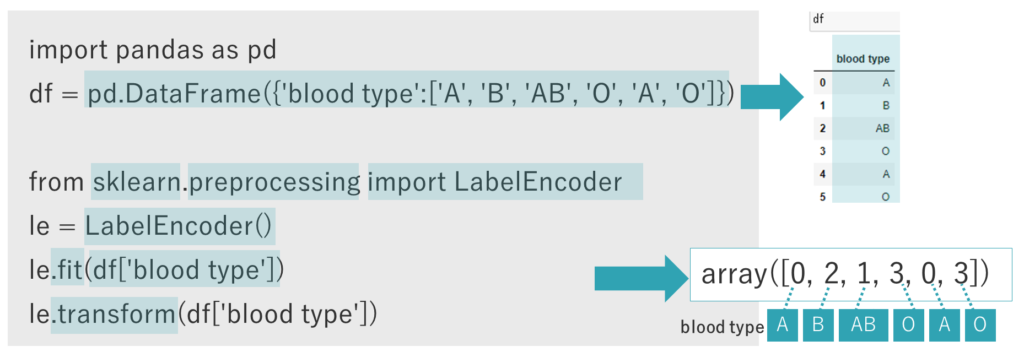
右のサンプルコードで確認します。
まずpandasでDataFrameを生成します。この時点で出力してみると、6行1列のblood type(血液型)の表が現れます。
そしてscikit-learnの前処理用モジュールである、preprocessingモジュールのLabelEncoderクラスをインポートします。
LabelEncoderのインスタンスを生成します。
先ほど生成したDataFrameをfitメソッドに与えて学習を実行し、transformメソッドでデータを変換します。
すると、先ほどの血液型が「数字」に置き換えられたことを確認できます。

なおscikit-learnのpreprocessingモジュールで前処理を行うときに使うクラスを教科書の範囲で整理しておきます。
いずれもfitメソッドで学習してからtransformメソッドで変換、あるいはfit_transformメソッドで学習と変換を一度に実行します。
選択肢②

選択肢②は正しい肢です。
One-hotエンコーディングについて教科書では、scikit-learnを用いる場合と、pandasを用いる場合とが扱われています。

scikit-learnを用いる場合は、以下のように行います。
例えば先ほどのデータフレームを使って、scikit-learnのpreprocessingモジュールのOneHotEncoderクラスをインポートし、OneHotEncoderのインスタンスを生成します。
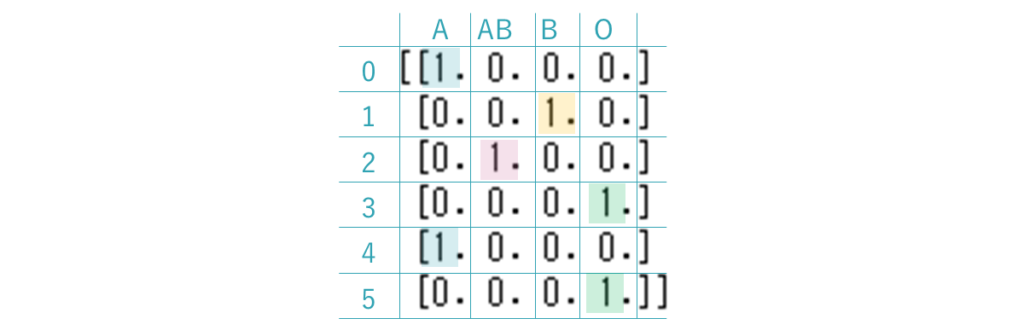
DataFrameをfit_transformメソッドに与えて学習と変換を一度に行って出力すると、0と1からなる行列となります。
余談ですが、この表は、いわゆる「疎行列」、つまり、たくさんの0と少しの1からなる行列です。toarrayメソッドを用いて、あえて見やすく、この形式にしています。
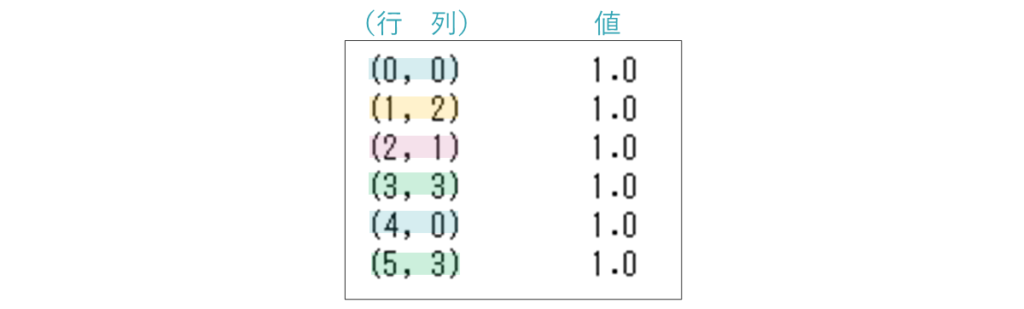
しかし疎行列は0を無視して扱うことによってメモリや計算量を削減できます。そのため実際に大量のデータを扱う際には、toarrayメソッドはあまり使われないのではないでしょうか。
toarrayメソッドを使わないで出力すると右のようになります。

ここまではscikit-learnを用いたOne-hotエンコーディングでしたが、もう一方のpandasを用いた場合を確認します。
get_dummies関数にデータフレームを渡すだけであり、コードがシンプルです。
scikit-learnを用いた場合と比較してみると、データの中身が同じであることを確認できます。
選択肢③

選択肢③は正しい肢です。
教科書では分散正規化と最小最大正規化の2つが扱われています。
選択肢④

選択肢④は誤りです。
分散正規化の説明ですが、特徴量の平均は0、標準偏差は1が正しいです。
選択肢⑤

選択肢⑤は正しい肢です。
第1回Python3データ分析模擬試験第33問の解説は以上です。