
本問題では「Matplotlib」のうち「ヒストグラムの出力方法(histメソッド)、正規分布に従う乱数の生成(random.normal関数)」について学びます。
本問題の解説はYouTube動画でもご覧いただけます。
【解説動画】 第1回Python3データ分析模擬試験 第31問
※当解説動画シリーズはPythonエンジニア育成推進協会に認定された「Python 3 エンジニア認定データ分析試験」の参考教材です。
問題
Matplotlibを用いて正規分布に従うランダムな値をヒストグラムで描画する次のコード群に関する説明のうち誤っているものはどれか。
import numpy as np
import matplotlib.pyplot as plt
np.random.seed(123)
mu = 100
sigma = 15
x = np.random.normal(mu, sigma, 1000)
fig, ax = plt.subplots()
n, bins, patches = ax.hist(x, bins=25, orientation=’horizontal’)
for i, num in enumerate(n):
print(‘{:.2f} – {:.2f} {}’.format(bins[i], bins[i + 1], num))
plt.show()
① 変数muは平均値を意味する。
② 変数sigmaは標準偏差を意味する。
③ ヒストグラムは横向きに描画される。
④ 出力されるテキストの行数は25行である。
⑤ このコード群を複数回実行した場合、必ずしも同じ結果になるわけではない。
解説
正解は選択肢⑤です。以下解説します。
コードの確認

まずnumpyとmatplotlib.pyplotをインポートします。
numpyのrandom.seed関数でシード値を設定し、スクリプトの再現性を確保します。

ここで選択肢の⑤が誤った内容であることを判断できます。

さらに変数muと、sigmaに値をそれぞれ格納します。
numpyのrandom.normal関数で正規分布に従う乱数を生成します。引数の一つ目は平均値、2つ目が標準偏差、3つ目が出力件数です。

ここで選択肢の①と②が正しい内容であることを判断できます。

そして、先ほど生成した正規分布に従う乱数を変数xに格納します。

なお、xを出力してみると、1000件の乱数が確認できます。

subplots関数で描画オブジェクトとサブプロットを生成します。
サブプロットaxにhistメソッドでヒストグラムを描画します。
引数の一つ目は先ほど生成した乱数です。その次のbins引数に(デフォルトとは異なる)25を指定し、orientation引数に「水平(横向き)」を指定します。
histメソッドの戻り値を3つの変数に格納します。

ここで選択肢③が正しい内容であることを確認できます。
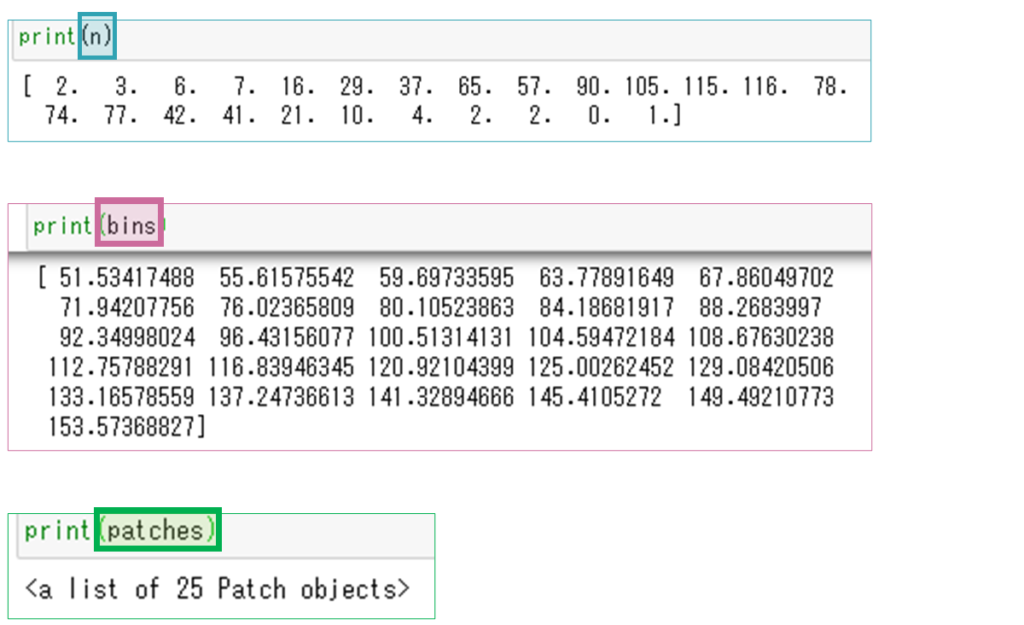
先ほどhistメソッドの戻り値を3つの変数n、bins、patchesに格納しました。それぞれ出力すると右のような値を確認できます。
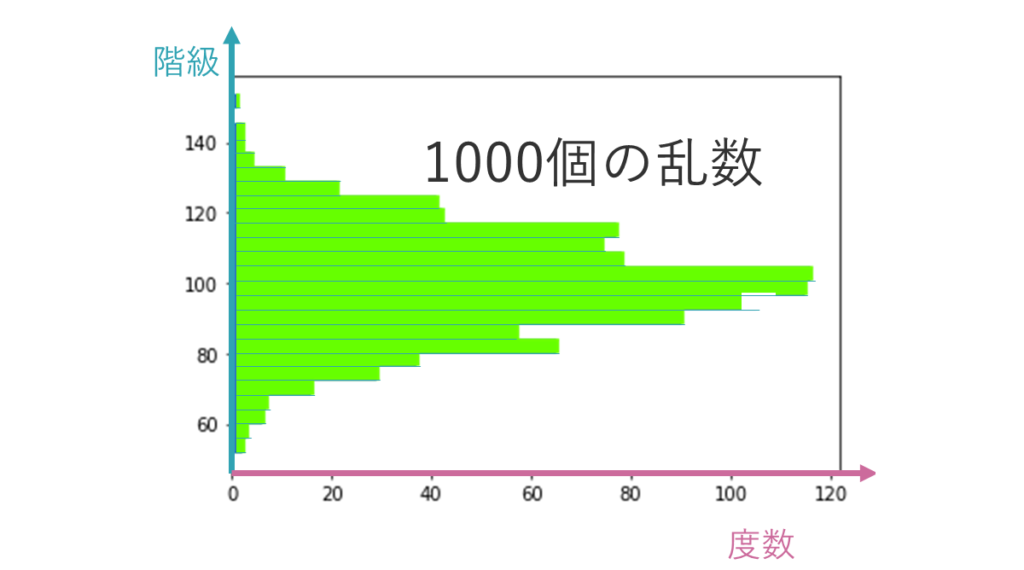
また右のような横向きのヒストグラムも確認できます。
このヒストグラムは、先ほど生成した1000個の乱数を小さい順に並べて25分割、つまり25個の階級で成り立っています。
ヒストグラムの縦軸は、階級です。
ヒストグラムの横軸は度数(ここでは各階級に属する「乱数の個数」)です。
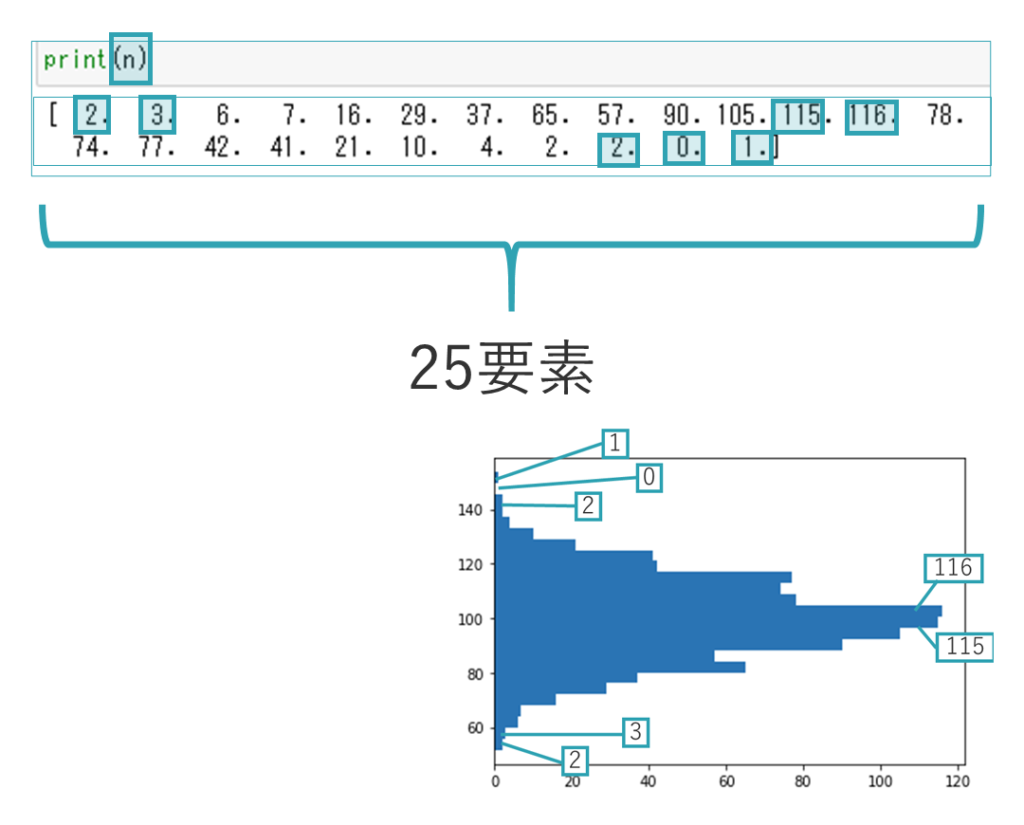
この場合の度数(乱数の個数)は25個あり、変数nに格納されています。
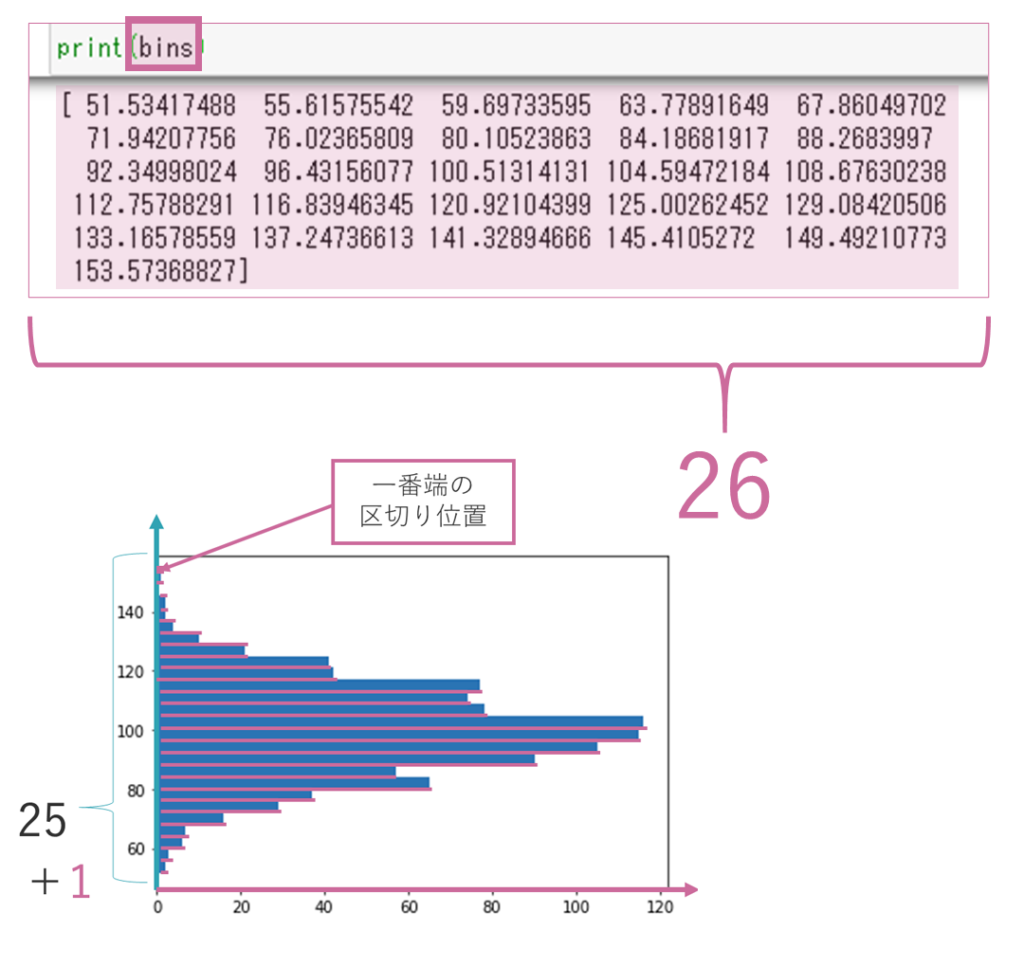
変数binsにはbinの区切り位置の値が格納されています。
値の個数は、ビンの数25+「一番端の区切り位置」=26個です。つまり変数binsは26個区切り位置の要素を持つ配列です。
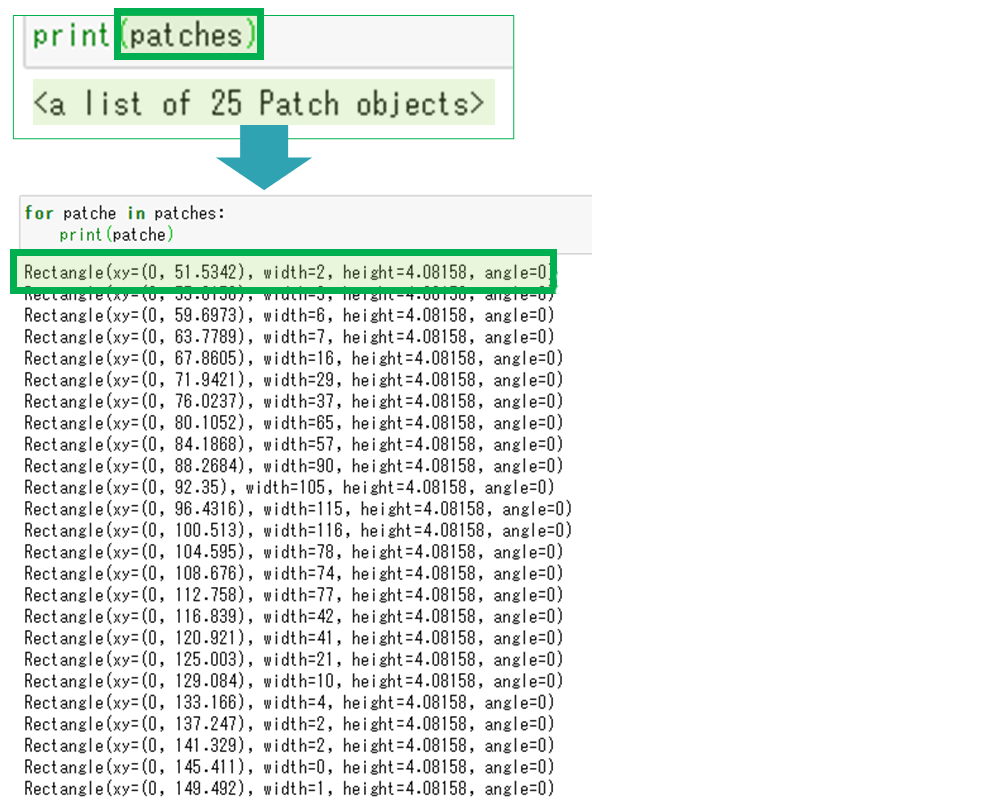
そしてpatchesはリストになっているため中身をfor文で取り出します。
するとそれぞれのbinの、描画に必要な情報が入っていることを確認できます。
左から順に、描画する長方形の開始位置、横幅、高さ、傾きです。これらの情報によって、一個の長方形・ビンが描画されています。

コードに戻ります。
度数が格納された変数nを、enumerate関数の引数に指定して、インデックス番号を取得します。
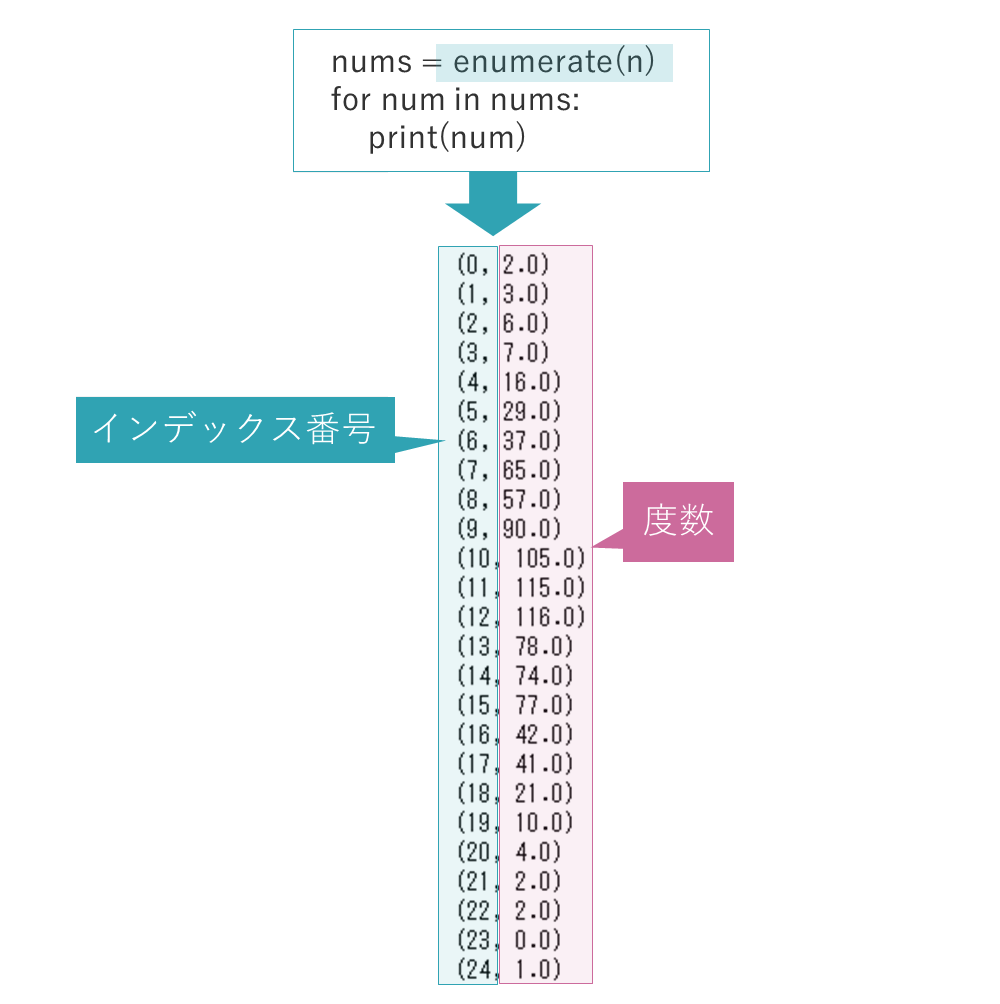
なお右のように出力すると、enumerate関数によってインデックス番号と度数が取得できることを確認できます。

enumerate関数の結果から、for文で、インデックス番号をiに、 度数をnumに順番に取り出します。そしてformatメソッドの引数や、binsのインデックスで使います。

具体的に見ていきます。
bins変数に格納されている、26個のbinの区切り位置(一つのbinを挟む上下両側の区切り位置)の値を順番に取り出します。
また引数のnumにはbinの度数が入ります。

これを繰り返して、文字列「{:.2f} – {:.2f} {}」に順番に入れていきます。

なお、文字列のカッコ1つめと2つめでは小数点以下2桁の指定がされています。
また先ほど確認した通り、インデックスは0から24までの合計25個、つまりfor文の繰り返しは25回です。
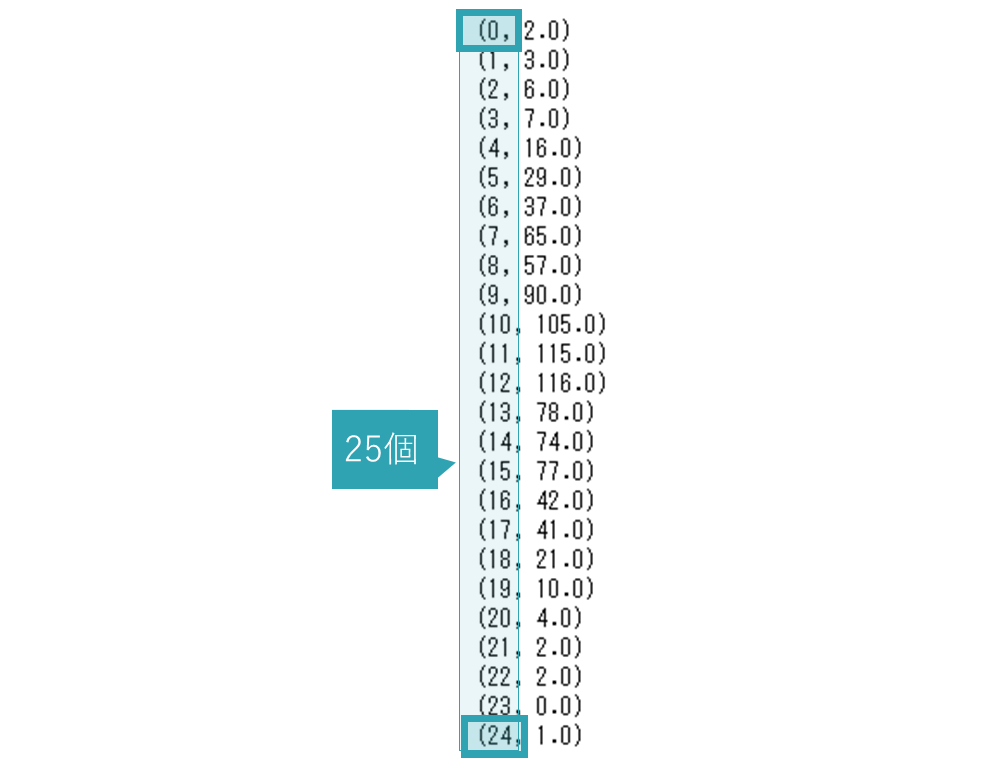
ですから、print関数で出力される文字列の行数も25行となります。

ここで選択肢④の内容が正しいことを確認できます。
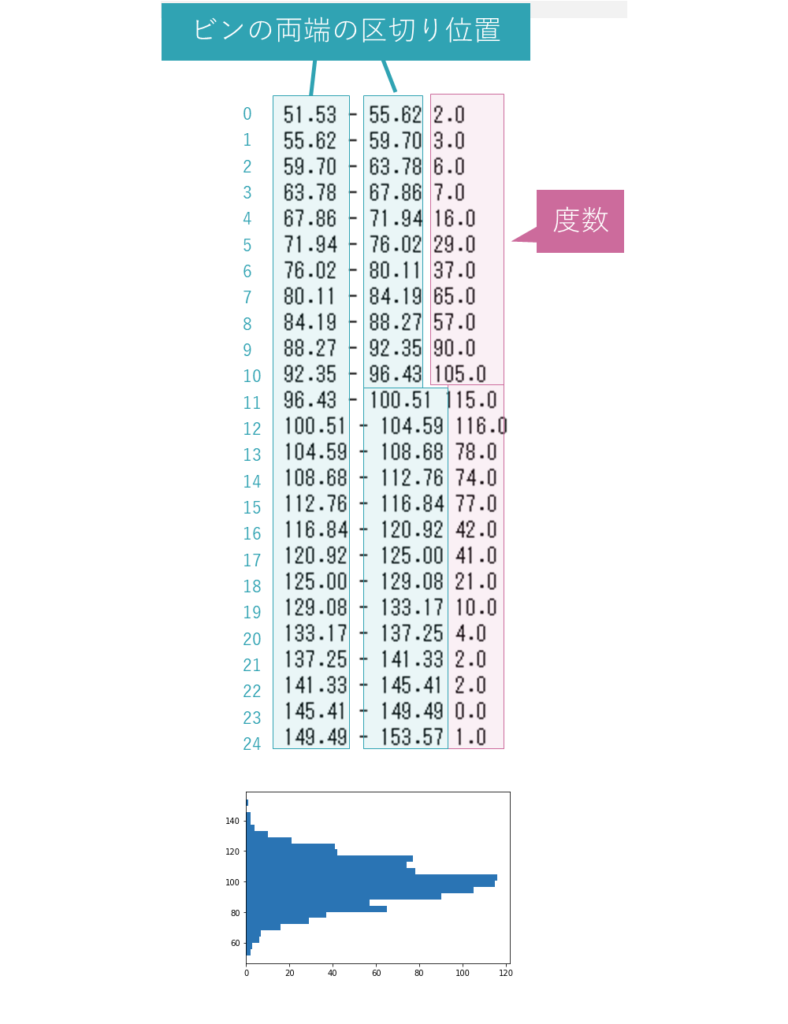

最後に出力すると、右のように表示されます。
各ビン・上下両端の区切り位置つまり各階級の幅・データの区間と、それぞれの度数が、インデックス順に25行分取得できています。
第1回Python3データ分析模擬試験第31問の解説は以上です。

