
本問題では「pandas」のうち「date_range関数を用いた時系列データの処理、乱数の生成」について学びます。
本問題の解説はYouTube動画でもご覧いただけます。
【解説動画】 第1回Python3データ分析模擬試験 第23問
※当解説動画シリーズはPythonエンジニア育成推進協会に認定された「Python 3 エンジニア認定データ分析試験」の参考教材です。
問題
次のスクリプトに関する説明のうち誤っているものはどれか。
import numpy as np
import pandas as pd
np.random.seed(123)
dates = pd.date_range(start=”2017-04-01″, periods=365)
df = pd.DataFrame(np.random.randint(1, 31, 365), index=dates, columns=[“rand”])df_year = pd.DataFrame(df.groupby(pd.Grouper(freq=’W-SAT’)).sum(), columns=[“rand”])
① 3行目は、乱数の発生に特定のシード値を与える処理である。これはスクリプトの実行結果の再現性を確保するための処理である。
② 4行目は、2017年4月1日から365日分の日付の配列を生成する処理である。periods=365 を end=”2018-03-31″ としても同じ結果となる。
③ 5行目は、日付をインデックスとするDataFrameを作成している。rand列の各値は、1から31までのランダムな整数となる。
④ 6行目は、土曜日の日付をインデックスとするDataFrameを生成する処理である。rand列の各値は日曜日から土曜日までのrand列の値を合計したものとなる。
⑤ 6行目の freq=”W=SAT” を freq=”M” に変更すると生成されるDataFrameの行数は12となる。
解説
正解は選択肢③です。以下解説します。
選択肢①
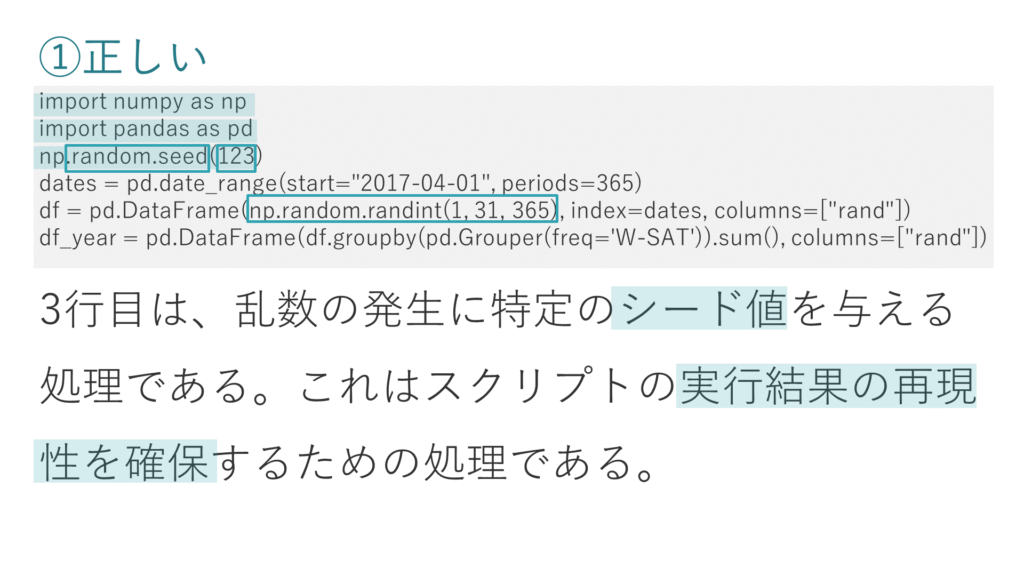
選択肢①は正しい肢です。
コードを上から順番に見ていきます。
まずnumpy とpandasをインポートします。
3行目では、numpyのrandom.seed関数でシード値が123に設定されています。
これによりこの後5行目で発生させる乱数が固定され、このスクリプトは何回実行しても同じ結果となる、つまり再現性が確保されることとなります。
選択肢②
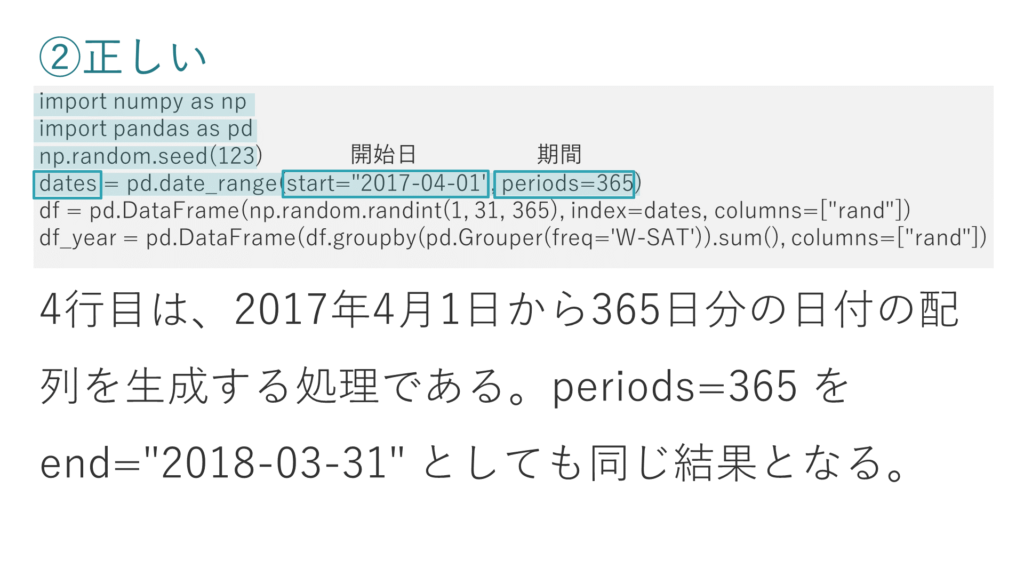
選択肢②は正しい肢です。
4行めではpandasのdate_range関数で開始日と期間を設定して、365日分の時系列データを生成しています。
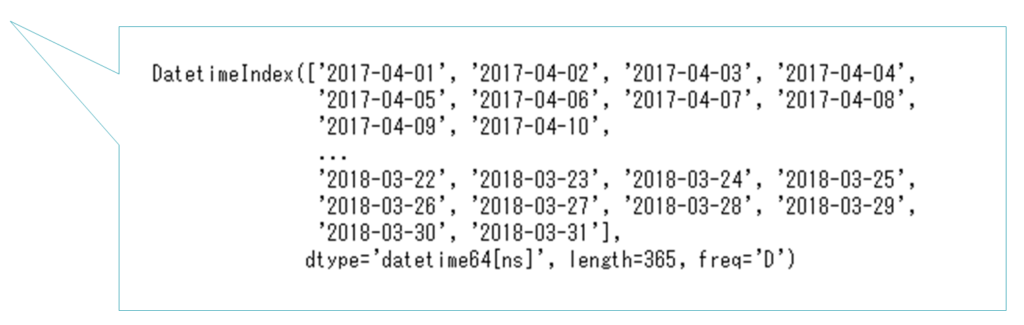
変数datesを出力すると、右のようであることを確認できます。
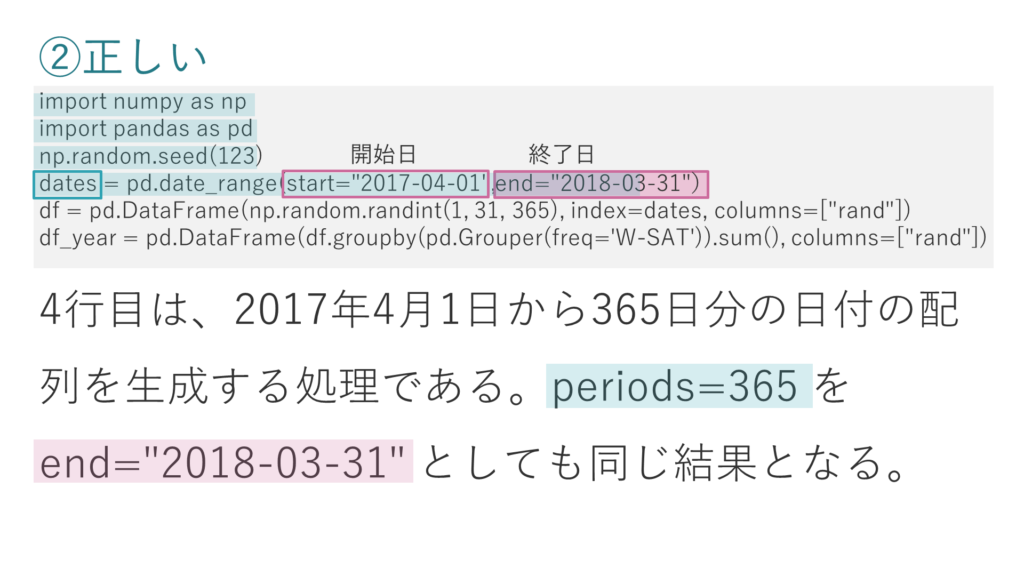
ここでdate.range関数に、開始日はそのままで、期間の代わりに終了日を設定しても、変数datesの出力結果は先ほどと変わりません。
選択肢③
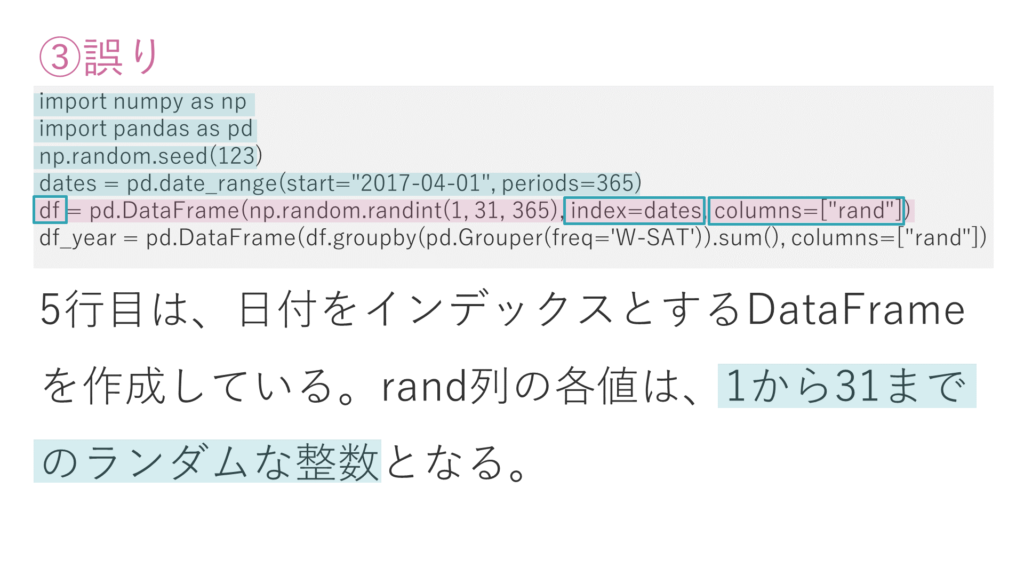
選択肢の③は誤りです。

5行目の変数dfを出力すると右のようであることが確認できます。
DataFrameを確認すると、まず行の名前は、先ほど生成した365日分の日付の配列、列の名前は「rand」という文字列です。
中身のデータ自体は、random.randint関数で生成されたランダムな整数です。

ここでrandom.randintに渡された引数をみると、生成する整数の範囲の最小値は1、最大値は「31の一つ手前」、つまり「30」までという指定がされていることがわかります(配列の形状は365行ということで特に問題ありません)。
そのため選択肢③の文章中「1から31までの」の部分が誤りであることを確認できます。
選択肢④
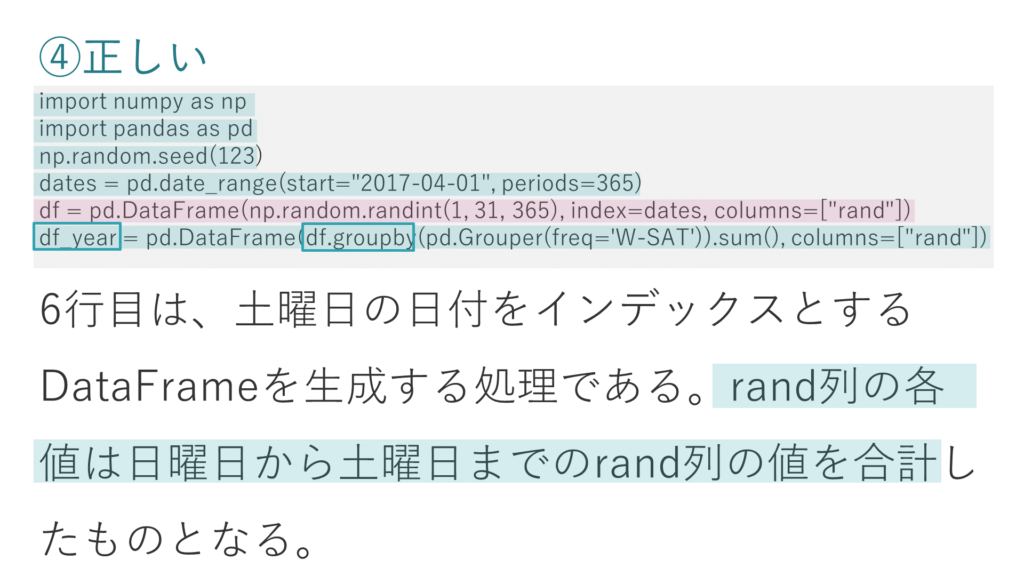
選択肢の④は正しいです。
6行目では、5行目までで生成された365日分の時系列のデータをもとに、pandasのgroubyメソッドを使ってサマライズを行っています。

df_yearを出力すると、右のように土曜日ごとの日付で要約されたデータが確認できます。
それぞれの値はGrouperで、365日分のデータを時系列に日曜から土曜まで1つのグループにして、そのグループごとの値を合計したものとなっています。
選択肢⑤

選択肢⑤は正しい肢です。
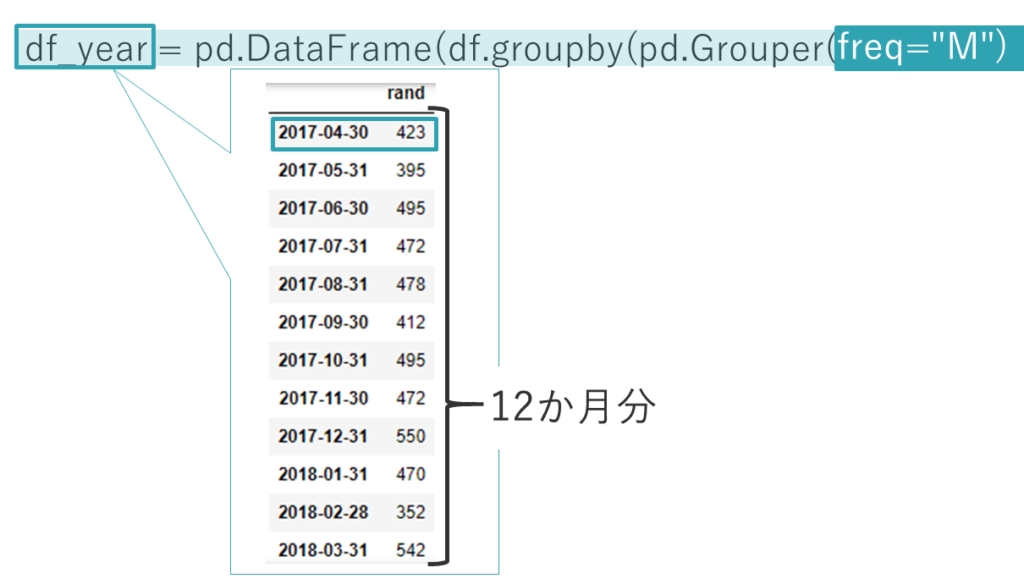
「freq=’W-SAT’」の部分を「freq=”M”」変更して、変数df_yearを出力すると、右のように、元のデータが1か月分の合計データに要約されていて、それが12か月分あることを確認できます。
第1回Python3データ分析模擬試験第23問の解説は以上です。

