
本問題では「Pythonと環境・Pythonの基礎」のうち「正規表現」について学びます。
本問題の解説はYouTube動画でもご覧いただけます。
【解説動画】 第1回Python3データ分析模擬試験 第05問
※当解説動画シリーズはPythonエンジニア育成推進協会に認定された「Python 3 エンジニア認定データ分析試験」の参考教材です。
問題
次の正規表現を用いたスクリプトの[ ア ]の部分に入れたときエラーと表示されるものはどれか。
import re
prog = re.compile(r'py?(th|ers)oni?(a[lmn]|c)?', re.IGNORECASE)
[ ア ]
if ret is None:
print('エラー')
else:
print(ret[0])
① ret = prog.search(‘Python’)
② ret = prog.search(‘personal’)
③ ret = prog.search(‘pythomian’)
④ ret = prog.search(‘PYTHONIC’)
⑤ ret = prog.search(‘The Zen of Python’)
解説
正解は選択肢③です。以下、解説していきます。
コードの確認

コードを上から順に確認します。
まず正規表現モジュールreをインポートします。
IGNORECASEフラグ(大文字小文字を区別しない)の設定をしたうえで、「compile」関数で正規表現オブジェクトを生成して、変数の「prog」に代入します。
正規表現パターンの文字列の前にrという文字がありますが、これはraw文字列記法というものです。正規表現パターンの文字列のエスケープを無効化するためによく記載されます。Python では正規表現パターンを記載する際にraw文字列記法を使うことが強く推奨されています。
「search」メソッドでカッコの中の文字列を走査して、正規表現パターンにマッチするところをマッチオブジェクトとして変数retに代入します。
if 文で変数retがNoneの場合、正規表現にマッチしなかったのでprint関数で「エラー」の文字を表示します。
変数retがNone以外の場合、正規表現にマッチしているのでprint関数でマッチした文字列全体を表示させます。
正規表現パターンの確認

正規表現にはシンタックスと呼ばれる特殊な表記法があります。(右図下部の表)
選択肢を見る前に、シンタックスを考慮した正規表現パターンを確認します。
- 【
py?】pから始まり、その直後のyは?(疑問符)がついていますので0(ゼロ)個もしくは1個という意味になります。つまり、pもしくはpyのどちらかのパターンになります。 - 【
(th|ers)】thもしくはersのどちらかのパターンになります。 - 【
oni?】onの直後のiには?がついていますので、onもしくはoniのどちらかのパターンになります。 - 【
(a[lmn]|c)?】少し複雑ですので1つずつ確認しながら考えます。[lmn]はl(エル)またはmまたはnのいずれか1文字のパターンです。つまりa[lmn]は、alまたはamまたはanのいずれかのパターンとなります。(a[lmn]|c)は、a[lmn]もしくはcのどちらかのパターンです。つまり、alまたはamまたはanまたはcのいずれかのパターンとなります。(a[lmn]|c)?は(a[lmn]|c)に?がついていますので、alまたはamまたはanまたはcのパターンが0個もしくは1個のパターンとなります。つまり、この部分のパターンは文字列の中になくても問題はないということです。
先ほど確認した通り、IGNORECASEフラグが設定されているので、大文字小文字を区別しないで考えます。
選択肢①

選択肢①の文字列は右図のようにマッチします。
ちなみにiおよび「al、am、an、c」の文字は選択肢①の文字列にはありませんが、そもそも0個(または1個)というパターンなのでマッチしなくてもエラーにはなりません。
選択肢②

選択肢②の文字列は右図のようにマッチします。
選択肢③
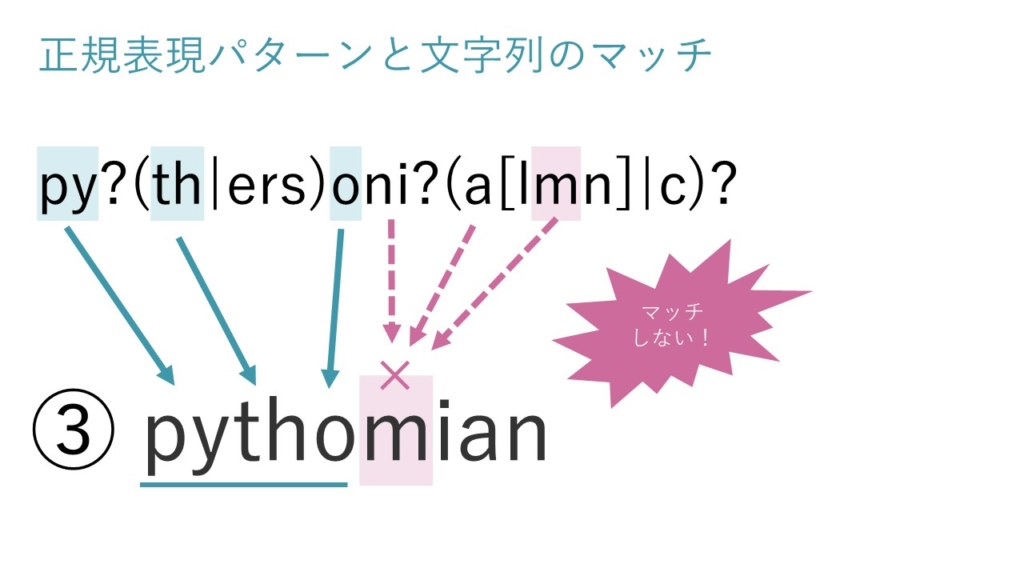
選択肢③の文字列のうち、pythoまではマッチしています。
しかし、oの次にマッチさせられる文字はnのみですが、選択肢③ではmが設定されていますのでマッチができません。
その後、正規表現にmの文字はありますが、こちらはamという並びの文字列にマッチします。
こちらのmでもマッチさせることはできません。
その結果、文字列全体としてどの部分にもマッチせず、選択肢③はエラーと表示されます。
選択肢④

選択肢④は右図のようにマッチします。
選択肢⑤
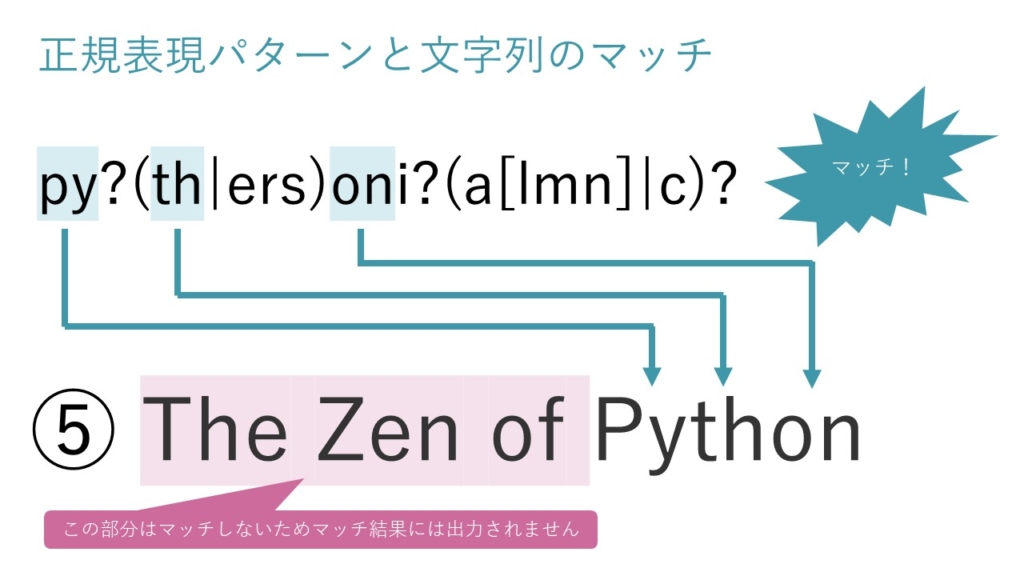
選択肢⑤は右図のようにマッチします。
「The Zen of 」の部分はマッチしないので、マッチした文字列を表示すると「Python」のみが表示されます。
「Python」部分のマッチの仕方自体は、選択肢①と同様です。
第1回Python3データ分析模擬試験第05問の解説は以上です。

