
本問題では「Pythonと環境・Pythonの基礎」のうち「リスト内包表記」について学びます。
本問題の解説はYouTube動画でもご覧いただけます。
【解説動画】 第1回Python3データ分析模擬試験 第04問
※当解説動画シリーズはPythonエンジニア育成推進協会に認定された「Python 3 エンジニア認定データ分析試験」の参考教材です。
問題
次のコード群の2行目以降を代替できるリスト内包表記として正しいものはどれか。
names = [‘spam’, ‘ham’, ‘eggs’ ]
lens =[]
for name in names:
lens.append(len(name))
lens
① [lens(name) in names for name]
② {lens(name) in names for name}
③ [lens(name) for name in names]
④ {len(name) for name in names}
⑤ [len(name) for name in names]
解説
正解は選択肢⑤です。以下、解説していきます。
内包表記
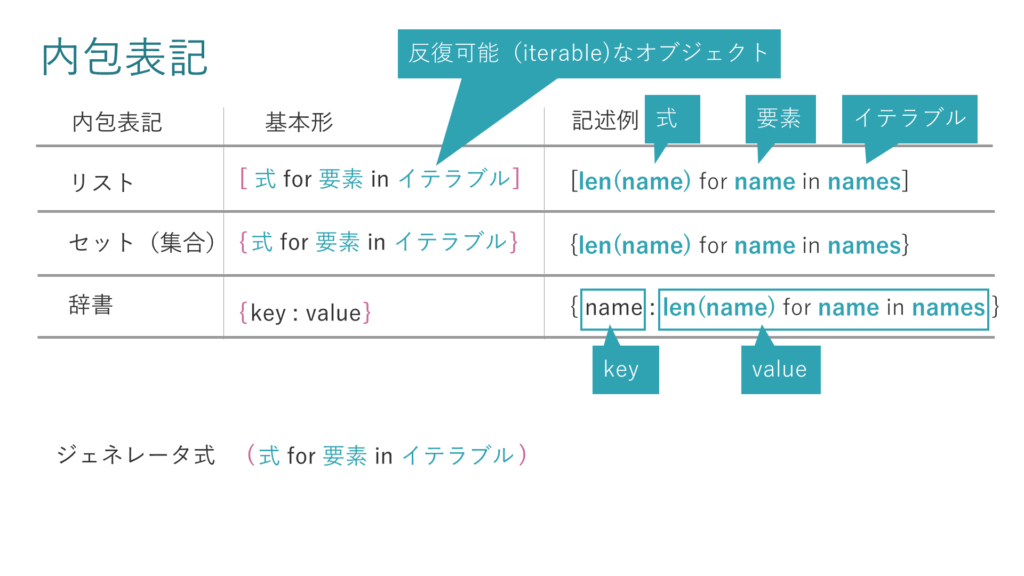
本問題のポイントはPythonの「リスト内包表記」です。その他の内包表記との対比でリスト内包表記を確認します。
ここでおさえておきたいのは、定義するときのカッコの形と、中身の定義の記述方法です。
リスト内包表記は角カッコ、セット内包表記と辞書内包表記は波カッコ、ちなみにジェネレータ式は丸カッコが使われます。
定義の記述の仕方はリストとセットとジェネレータ式が同様で、「式 for 要素 in イテラブルオブジェクト」つまり要素を1つずつ取り出せる構造のオブジェクトです。
辞書だけがkey とvalueの形です。
コードの確認

ここでコードを上から順に確認します。
まずリストを2つ作っています。namesは3つの文字列を格納したリスト、lensは空のリストです。
namesリストをfor文で回し変数「name」に文字列を取り出します。
そのたびに「len()」関数を使い、文字列の文字数を取得して、空のlensリストの最後にappendメソッドで加えます。
最後に出力すると右図の右下のようになります。
選択肢①~⑤

ここで選択肢を確認します。今回は消去法で検討してみましょう。
②と④はリスト内包表記ではなくセット内包表記なので候補から外れます。
残った選択肢のうち、①と③はlen関数ではなくリストの「lens」、つまりfor文の直前が文字列の長さを取り出す式になっていないのでこれらも候補から外れます。
結局、残った選択肢⑤が正しいということになります。
第1回Python3データ分析模擬試験第04問の解説は以上です。


