
本問題では「pandas」のうち「条件によるデータ抽出」について学びます。
本問題の解説はYouTube動画でもご覧いただけます。
【解説動画】 第1回Python3データ分析模擬試験 第22問
※当解説動画シリーズはPythonエンジニア育成推進協会に認定された「Python 3 エンジニア認定データ分析試験」の参考教材です。
問題
次のスクリプトを実行した結果として正しいものはどれか。
import pandas as pd
df = pd.DataFrame([[40, “a”, True],[20, “b”, False],[30, “c”, False]])
df.index = [“01”, “02”, “03”]
df.columns = [“A”, “B”, “C”]
def judge(arg):
if arg < 50:
return “low”
elif arg < 70:
return “middle”
else:
return “high”
df.loc[:, “C”] = df.iloc[:, 0] * 2
df.loc[:, “B”] = df.iloc[:, 2].apply(judge)
_ = df[“C”] > 50
df = df[_]
print(df.iloc[0 , 0], df.iloc[1 ,1])
① 20 middle
② 30 middle
③ 40 middle
④ 30 high
⑤ 40 high
解説
正解は選択肢③です。以下解説します。
コードの確認

選択肢を見る前に、コードを上から順に確認します。
まずpandasをインポートして、3×3のDataFrameを生成します。
また行の名前を任意の数値で、列の名前を任意の文字列で、それぞれ指定します。
ここまで(右図青枠部分)を出力してみます。
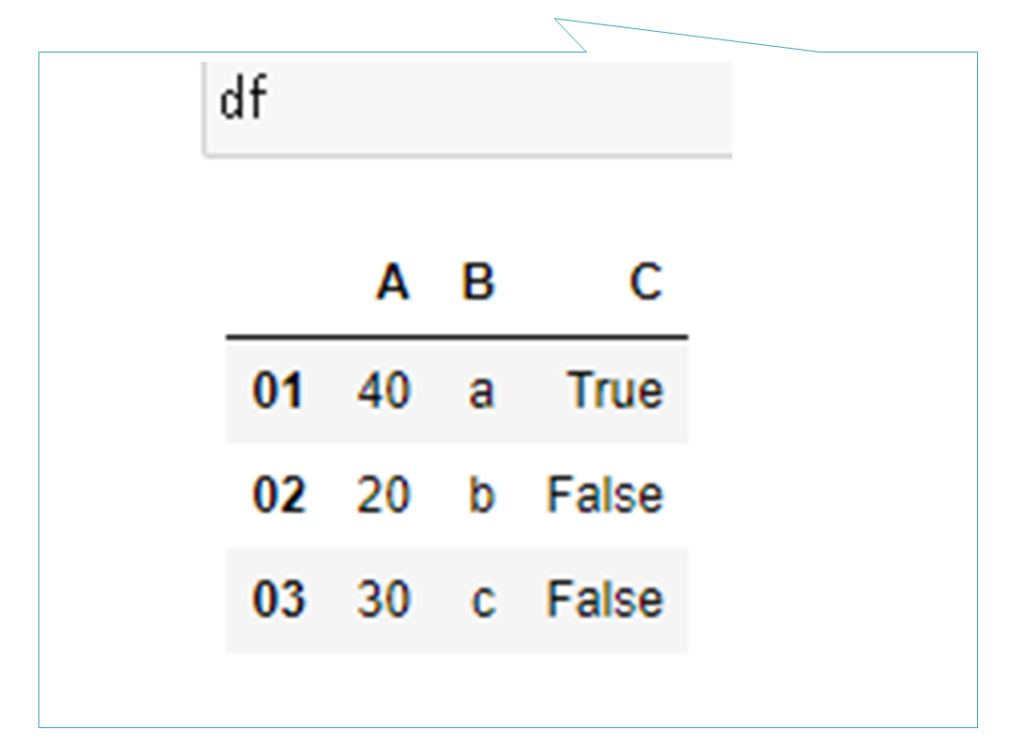
すると右のようなDataFrameが確認できます。このデータ構造を見ながら、以下のコードを確認していきます。

次に「judge」という関数を、右の表のような条件のものとして定義します。
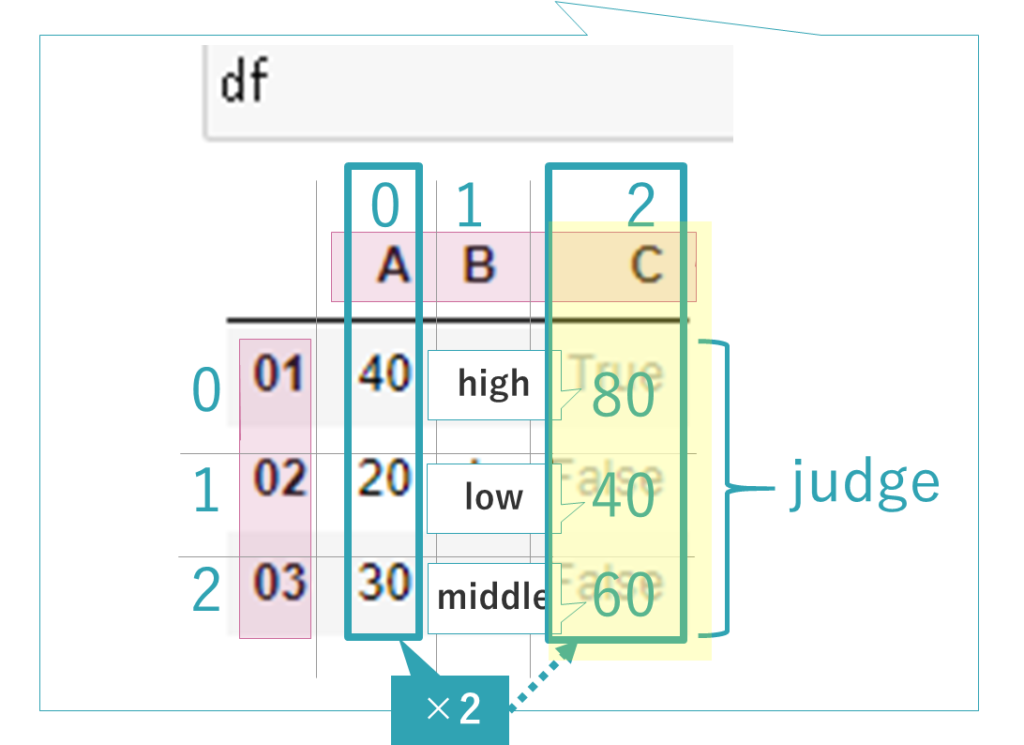

そして、すべての行にわたる0列目の値に2を掛け、その値を、すべての行のCの列に上書きします。
またすべての行の2列目、つまり先ほどと同じCの列の値にapplyメソッドでjudge関数を適用し、返された値をそれぞれBの列に上書きします。
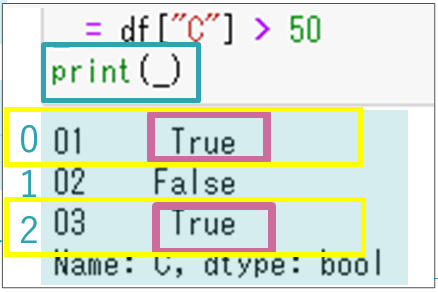

さらにC列のうち50より大きい値を抽出してアンダースコア(「_」)に格納します。
このアンダースコアをprint関数で出力してみると、右のようであることを確認できます。
これはC列の各行の値が、「50より大きい」という条件にマッチしているかどうかがTrueまたはFalseで表されたbool型のSeriesです。


そのSeriesをDataFrameに当てはめて、Trueの行(番号で0と2の行)のみ抽出し、変数dfを上書きします。
このdfを出力してみると、右のようであることを確認できます。
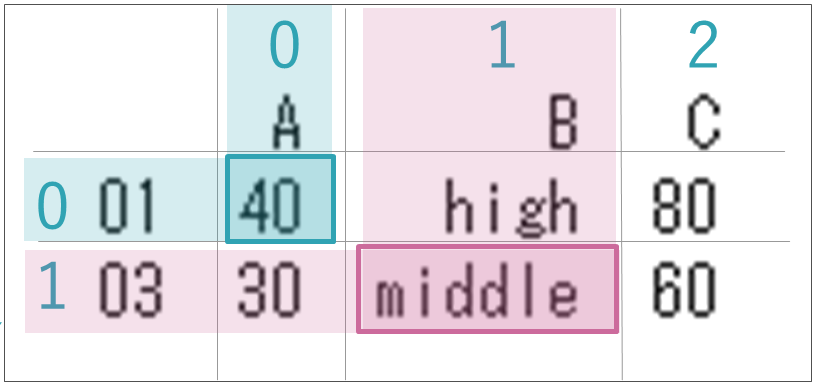
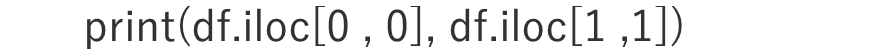
最終的にprint関数で、dfの0行0列(青枠)と1行1列(赤枠)の部分を出力すると、40とmiddleが答えとして導かれます。
選択肢①~⑤

以上から、選択肢③が正しいことを確認できます。
第1回Python3データ分析模擬試験第22問の解説は以上です。